安装 NVIDIA vGPU Addon¶
如需将一张 NVIDIA 虚拟化成多个虚拟 GPU,并将其分配给不同的云主机或用户,您可以使用 NVIDIA 的 vGPU 能力。 本节介绍如何在算丰 AI 算力平台中安装 vGPU 插件,这是使用 NVIDIA vGPU 能力的前提。
前提条件¶
- 参考 GPU 支持矩阵 确认集群节点上具有对应型号的 GPU 卡。
- 当前集群已通过 Operator 部署 NVIDIA 驱动,具体参考 GPU Operator 离线安装。
操作步骤¶
-
功能模块路径: 容器管理 -> 集群管理 ,点击目标集群的名称,从左侧导航栏点击 Helm 应用 -> Helm 模板 -> 搜索 nvidia-vgpu 。
-
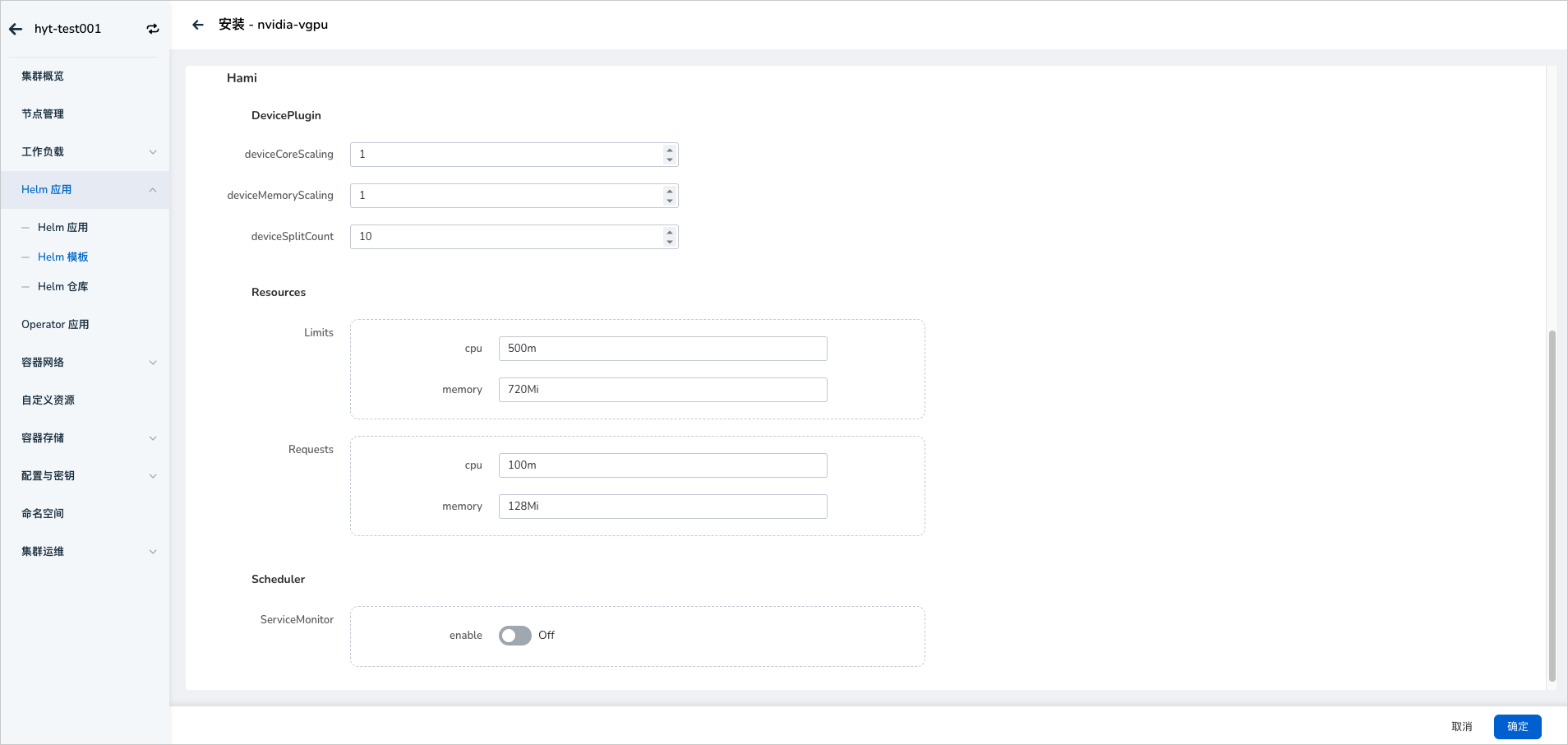
在安装 vGPU 的过程中提供了几个基本修改的参数,如果需要修改高级参数点击 YAML 列进行修改:
-
deviceCoreScaling :NVIDIA 装置算力使用比例,预设值是 1。可以大于 1(启用虚拟算力,实验功能)。如果我们配置 devicePlugin.deviceCoreScaling 参数为 S,在部署了我们装置插件的 Kubernetes 集群中,这张 GPU 分出的 vGPU 将总共包含 S * 100% 算力。
-
deviceMemoryScaling :NVIDIA 装置显存使用比例,预设值是 1。可以大于 1(启用虚拟显存,实验功能)。 对于有 M 显存大小的 NVIDIA GPU,如果我们配置 devicePlugin.deviceMemoryScaling 参数为 S, 在部署了我们装置插件的 Kubernetes 集群中,这张 GPU 分出的 vGPU 将总共包含 S * M 显存。
-
deviceSplitCount :整数类型,预设值是 10。GPU 的分割数,每一张 GPU 都不能分配超过其配置数目的任务。 若其配置为 N 的话,每个 GPU 上最多可以同时存在 N 个任务。
-
Resources :就是对应 vgpu-device-plugin 和 vgpu-schedule pod 的资源使用量。
-
ServiceMonitor :默认不开启,开启后可前往可观测性模块查看 vGPU 相关监控。如需开启,请确保 insight-agent 已安装并处于运行状态,否则将导致 NVIDIA vGPU Addon 安装失败。
-
-
安装成功之后会在指定 Namespace 下出现如下两个类型的 Pod,即表示 NVIDIA vGPU 插件已安装成功:

安装成功后,部署应用可使用 vGPU 资源。
Note
NVIDIA vGPU Addon 不支持从老版本 v2.0.0 直接升级为最新版 v2.0.0+1; 如需升级,请卸载老版本后重新安装。